FAQs: Unicode Support for Sites Running Oracle
Availability of Unicode Support for SirsiDynix Symphony Systems
Unicode™ is a universal encoding scheme adopted by the major hardware and software manufacturers which is designed to support the worldwide interchange, processing, and display of diverse languages.
SirsiDynix Symphony provides optional Unicode support for sites running Oracle. SirsiDynix Symphony with Unicode allows staff to perform the following actions:
|
•
|
Import and export MARC records which contain multiple scripts |
|
•
|
Input and edit multiple scripts in a single MARC record using the WorkFlows Java client |
|
•
|
Index, search and display multi-script records in WorkFlows and OPAC clients |
Implementation does require that your existing MARC data be converted. Additionally, attending a Unicode Planning and Implementation workshop is required. Please contact your SirsiDynix Client Sales consultant for pricing and scheduling information.
Converting SirsiDynix Symphony Data to Unicode
During the conversion to Unicode, the following SirsiDynix Symphony data will be converted:
|
•
|
All MARC records, including bibliographic, authority, and holding records |
|
•
|
All SirsiDynix Symphony text data, such as patron names, addresses, and extended information fields |
After your system is converted to Unicode, you will be able to input and edit multiple scripts in a single record using your WorkFlows Java client. There are three methods for entering non-Roman scripts.
|
•
|
Using the WorkFlows Java client Symbol Table helper |
|
•
|
Using Microsoft international keyboards |
|
•
|
Using Microsoft-supported IME (Input method editor) |
The MARC load programs will be able to handle records that contain multiple scripts, Roman and non-Roman. These programs will detect non-Unicode data and convert the data to Unicode when loading records. The SmartPort wizard will be able to capture Unicode and non-Unicode data and will also convert non-Unicode data when loading records.
The WorkFlows Java client and the SirsiDynix Symphony e-Library products (iBistro, iLink, and Web2) will be able to index, search, and display multi-script records.
Export programs will support output in Unicode (UTF-8) and MARC-8.
Preparing for the Unicode Conversion
To use this SirsiDynix Symphony feature, administrators need to do the following:
|
•
|
Upgrade the test server and production server to Unicorn Version GL3.1 or later, or SirsiDynix Symphony Version 3.2 or later |
|
•
|
Upgrade all staff workstations to the Unicorn Version GL3.1 WorkFlows Java client or later, or SirsiDynix Symphony WorkFlows Java client Version 3.2 or later |
|
•
|
Purchase Unicode Extension licenses for test and production servers |
|
•
|
Schedule the Unicode Planning and Implementation Workshop |
|
•
|
Schedule the MARC21 to Unicode migration |
|
•
|
For existing records with non-Roman scripts, obtain the latest version of these records from a bibliographic utility |
|
•
|
After migrating the test and production servers to Unicode, rebuild SirsiDynix Symphony indexes |
Software Requirements
|
•
|
Oracle version 9.2.0.7 or 10.1.0.5, or later |
|
•
|
Unicorn Version GL3.1 server or later, or SirsiDynix Symphony Version 3.2 or later |
|
•
|
Unicorn Version GL3.1 WorkFlows Java client or later, or SirsiDynix Symphony WorkFlows Java client Version 3.2 or later, on all desktops |

Non-WorkFlows Java clients will not connect to a SirsiDynix Symphony server with the Unicode Server Extension.
Hardware Requirements
|
•
|
Possible server upgrade since disk storage and memory will be approximately 50 percent higher than the requirements for running the current version of SirsiDynix Symphony on Oracle |
|
•
|
Latest version of your hardware platform operating system |
Contact your SirsiDynix Client Sales consultant for more information.
Indexing the 880 Tag in Unicode Records
Bibliographic titles on a SirsiDynix Symphony Unicode server often contain 880 fields which contain Alternate Graphic Representations of text found in another field of the same record. The two fields are linked via the subfield 6. For detailed information about the 880 field, see MARC 21 Concise Bibliographic: Holdings, Location, Alternate Graphics, etc. Fields (http://www.loc.gov/marc/bibliographic/ecbdhold.html#mrcb880). Because of this special relationship, SirsiDynix Symphony handles the indexing of an 880 field as follows.
When an 880 tag is indexed, the indexing looks at the 880 subfield 6 to determine the field to which it is linked. In the case of |6245, it then indexes the 880 the same as it would the 245 field.
For example, there is a record with the following fields.


SirsiDynix Symphony handles the 880 tag indexing in the same manner on Unicode and non-Unicode servers.
You can perform a keyword title search for ”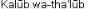 ” or by typing the Arabic characters ”
” or by typing the Arabic characters ”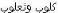 ” to retrieve the bibliographic record.
” to retrieve the bibliographic record.
SirsiDynix Symphony Unicode Indexing of Upper/lower Case Characters, Punctuation, Diacritics, and Special Characters
There are differences between how SirsiDynix Symphony non-Unicode and Unicode systems handle browse and keyword indexing of upper and lower case characters, punctuation, diacritics, and special characters.
Basically, for browse indexes, the initial text string normalization is exactly the same between non-Unicode and Unicode systems, except that SirsiDynix Symphony Unicode now retains characters, such as diacritics, and all other non-English characters in the index so that the natural language ordering of the data can take place based on Oracle’s implementation of the Unicode Collating Sequence Standard (ISO 14651). For keyword indexes, the initial normalization is exactly the same, removal of diacritics is the same, but SirsiDynix Symphony Unicode uses a new routine to break text into words (primarily for foreign language support), and there is some new special processing in place for ideographic characters.
SirsiDynix Symphony Unicode systems store data composed, if at all possible. “Composed” means that a character with a diacritic, such as À, is stored as a single Unicode character. “Decomposed” means that the character with a diacritic is stored as two characters, the Unicode character A followed by the Unicode diacritic character.
SirsiDynix Symphony Unicode Browse Indexes and Browse Strings
When browse indexes are created, the following normalization processes take place.
|
•
|
Letters are converted to their upper case equivalents in all languages, which is similar to non-Unicode systems. |
|
•
|
Most Latin punctuation marks are removed, also similar to non-Unicode systems, although this is not required since Unicode uses natural language indexes, which ignore the punctuation. |
|
•
|
All non-spacing modifiers, such as diacritics, are retained and combined into a single character, if this is possible. This is unique to Unicode systems. |
|
•
|
All other characters are retained unless there is a translation of that character to another character or set of characters in a custom file /Unicorn/Custom/characters-utf8. Not all systems use this custom file. If not, characters such as slash o, thorn, and more are retained. |
After the normalization process, the resulting string of characters is what is added to the heading tables, which use Oracles’s natural language indexing for ordering. This determines the order of the display headings.
SirsiDynix Symphony Unicode Keyword Indexes and Search Strings
When keyword indexes are created, the following normalization processes take place.
|
•
|
Letters are converted to their upper case equivalents in all languages, which is similar to non-Unicode systems. |
|
•
|
Most Latin punctuation marks are removed, also similar to non-Unicode systems. |
|
•
|
Remaining individual characters are translated to another character or set of characters based on a custom file /Unicorn/Custom/characters-utf8. Not all systems use this custom file. If not, characters such as slash o, thorn, and more are retained. |
|
•
|
The resulting text is broken into words, except for ideographic characters, such as Chinese (CJK), which are retained as entered. If a word begins with the Arabic characters ALEF U + 0627 and LAM U + 0633, those two characters are removed. This is unique to Unicode systems. |
|
•
|
Text is decomposed, and all non-spacing modifier characters, such as diacritics, are removed, also similar to non-Unicode systems. |
|
•
|
Ideographic characters are segmented into words based on a CJK dictionary delivered in /Unicorn/Sino/cjklex.tbl-utf8. This is unique to Unicode systems. |
|
•
|
Ideographic characters are then translated from traditional Chinese to simplified Chinese, based on the table delivered in /Unicorn/Sino/tradsmpl.tbl-utf8. This is unique to Unicode systems. |
Bidirectional enhancements
The WorkFlows Java client has been enhanced to more correctly display MARC record text recorded in languages that have a right–to–left orientation such as Arabic and Hebrew and also in cases where the text has been recorded using a combination of right–to–left and left–to–right scripts (bidirectional).
The Java client has always supported the Unicode Bidirectional Algorithm which is defined in the Unicode standard. This algorithm determines where a certain character will be displayed within a text string depending on the character directionality and main component orientation.
The following changes have further enhanced the WorkFlows Java client’s ability to display and edit bidirectional text beyond the limitations of the Unicode Bidirectional Algorithm.
|
•
|
Fields that contain right–to–left script data now display right–justified by default |
|
•
|
A new helper, Add Subfield Delimiter/Code, assists in the addition of new subfield delimiters/codes when cataloging in a right–to–left language |
|
•
|
Two helpers added to allow entry of Unicode formatting characters |
|
•
|
Unicode formatting characters can now be deleted in the MARC editor |
|
•
|
Hit list capable of displaying alternate graphic representation information from the linking 880 field |
When using the WorkFlows Java client MARC editor to add or edit right–to–left fields the following rules apply
|
–
|
Editing a field using expanded field mode does not support the display, addition, deletion, or modification of Unicode formatting characters. |
|
–
|
The Add Subfield Delimiter/Code helper can not be used to add new subfields while using expanded field mode. |
|
–
|
When adding a new subfield manually to a right–to–left field in single field mode, Unicode formatting characters are NOT automatically added before or after the subfield delimiter/code. |
|
–
|
When adding a new subfield to a right–to–left field using the Add Subfield Delimiter/Code helper in single field mode, Unicode formatting characters are automatically added before and after the subfield delimiter/code. |
Right–to–Left Script Data Displays Correctly in WorkFlows Java Client
The orientation of field/subfield contents cell in the MARC editor is now determined based on the script used to record the field’s data. If any characters with strong right–to–left directionality are encountered, the field orientation will be set right–to–left and the text of the field will be displayed right–justified. If the data contains no characters with strong right–to–left directionality, the field will be rendered left–to–right. Expanded mode will display individual subfields according to their field orientation.
|
•
|
On the search window view pane Description tab, if the data contains any strong right–to–left characters, the component orientation will now be set to right–to–left and vice versa. |
|
•
|
Open wizards when switching toolbars in themes view will only be repainted when switching between right–to–left and left–to–right. |
|
•
|
Text directionality is taken into account when printing from cataloging (File/Print, File/Print Preview, File/ Screen) |
|
•
|
Bibliographic Description helper applies the correct script orientation per MARC field. |
|
•
|
If truncated, the Current Title/Author adds ellipses in the correct order (to the left) if any strong right–to–left characters are encountered. |
Add Subfield Delimiter/Code Helper Allows Entry of Non–Latin Data
The Add Subfield Delimiter/Code helper allows the input of subfield delimiters and codes in a MARC record without the need to change to a Latin keyboard or use the MARC editor’s expanded field mode. This helper is available on both Unicode and non–Unicode servers but was primarily designed for use by those who routinely catalog in non–Latin languages. By default, this helper will not appear.
An alternative method is to press CTRL+D while entering records, which allows subfields to be edited in one language and the keyboard returned to the original language when entry is complete.
This option only works under the following conditions:
|
•
|
The server is a Unicode server. |
|
•
|
The input keyboard layout at the time CTRL+D is invoked is other than English. |
|
•
|
The host platform has at least one English language keyboard layout active. |
For example, if the input language is French and an English language or keyboard is installed, CTRL+D inserts the subfield delimiter and changes the language to English for entry of the subfield code. After entry of the subfield code, the input language returns to French. If CTRL+D inserts a subfield delimiter/code in a field containing characters with strong right directionality, the subfield delimiter/code will be embedded in RLM (right-to-left mark) characters consistent with usage in the Add Subfield Delimiter/Code helper.
Added Support for UNICODE Formatting Characters
Two helpers have been added to allow entry of Unicode formatting characters.
|
•
|
Add Unicode Formatting Characters Helper — This helper displays a list of Unicode format characters that can be added to the MARC record. |
|
•
|
Show/Hide Unicode Formatting Characters Helper — This helper allows you to toggle on/off the display of embedded Unicode format characters in the MARC record while using the MARC editor. |
Unicode formatting characters may be needed primarily to change the default display produced by the Unicode Bidirectional Algorithm. These characters are used to change the direction of display of right–to–left within left–to–right or left–to–right within right–to–left because not all characters have a defined or strong display direction. This algorithm cannot always make the correct determination as to how one or more characters are to be displayed, and therefore the Unicode formatting characters are used to control that algorithm, so that the characters are displayed in a manner that is pleasing to the user. These formatting characters would generally only be used by those who routinely catalog in non–Latin languages. By default, these helpers will not appear.
UNICODE Formatting Characters Can Be Deleted in MARC Editor
Formatting characters are defined in Unicode as zero–width characters. In order to delete formatting characters, they must be selected. Selection can be made with either the keyboard (hold Shift key down and use right or left arrow to move the caret) or a mouse. When on a formatting character, the caret will change its shape from standard flagged to rectangle outline around the character, hitting the Delete key when the rectangle is displayed around the formatting character will delete it.
Search Hit List Can Display Alternate Graphic Representation Information from the Linked 880 Field
A keyword search in the WorkFlows Java client has been enhanced to allow the display of text from a corresponding 880 if it exists. This is controlled by the new Global Configuration policy Display of 880 on Search Hit list. This policy will only display on a Unicode server and has the following options
|
•
|
Display only the regular (non-880) entries (this is the delivered default) |
|
•
|
Display both the regular (non-880) entries followed by the linked 880 entries |
|
•
|
Display only the linked 880 entries (Note that if a linked 880 does not exist, display the regular (non-880) field) |